Every LLM session gets
more expensive as it runs.
That's arithmetic. Not a bug.
Turn N replays the whole transcript as input, so turn N costs proportional to N and the session costs O(N²). That is arithmetic from the pricing page, not a property of any SDK.
Burnless stops replaying it. Not by asking the LLM to be careful. By separating Cognitive Execution (Workers) from State Management (Capsules/Maestro) — the same design move TCP/IP made when it separated applications from the network. Same move, not the same scale: TCP/IP defines internet infrastructure; Burnless is a small MIT Python framework that wires caching, tier routing and capsules together in a particular way. Workers receive the current task only. The Brain reads ~80-character capsules instead of transcripts, and the system prefix stays byte-identical, so the provider's cache stays hot.
Measured, not promised: a real paid API run — $5.76 of actual spend against claude-opus-4-7, raw response.usage, no mocks — cut turn-10 cost by 90.3% vs no-cache replay, and a further ~30% vs an already-cached replay baseline. The gap grows with session length. Reproduce it with your own key: python bench/run.py --turns 10.
Three receipts from the author's own machines: 121 million tokens kept out of context since 2026-05-18, logged turn by turn in an append-only JSONL. One order-of-magnitude week — 97% of weekly quota down to 1% on comparable work. And one full workday that processed 1.44M tokens while the context window carried 1,590 — 908× less context, and it survives /clear. The first is a measurement; the other two are single-machine anecdotes, labeled as such. We once shipped an inflated "16×" and retracted it — the honest numbers turned out stranger than the inflated one. All three are why this project exists.
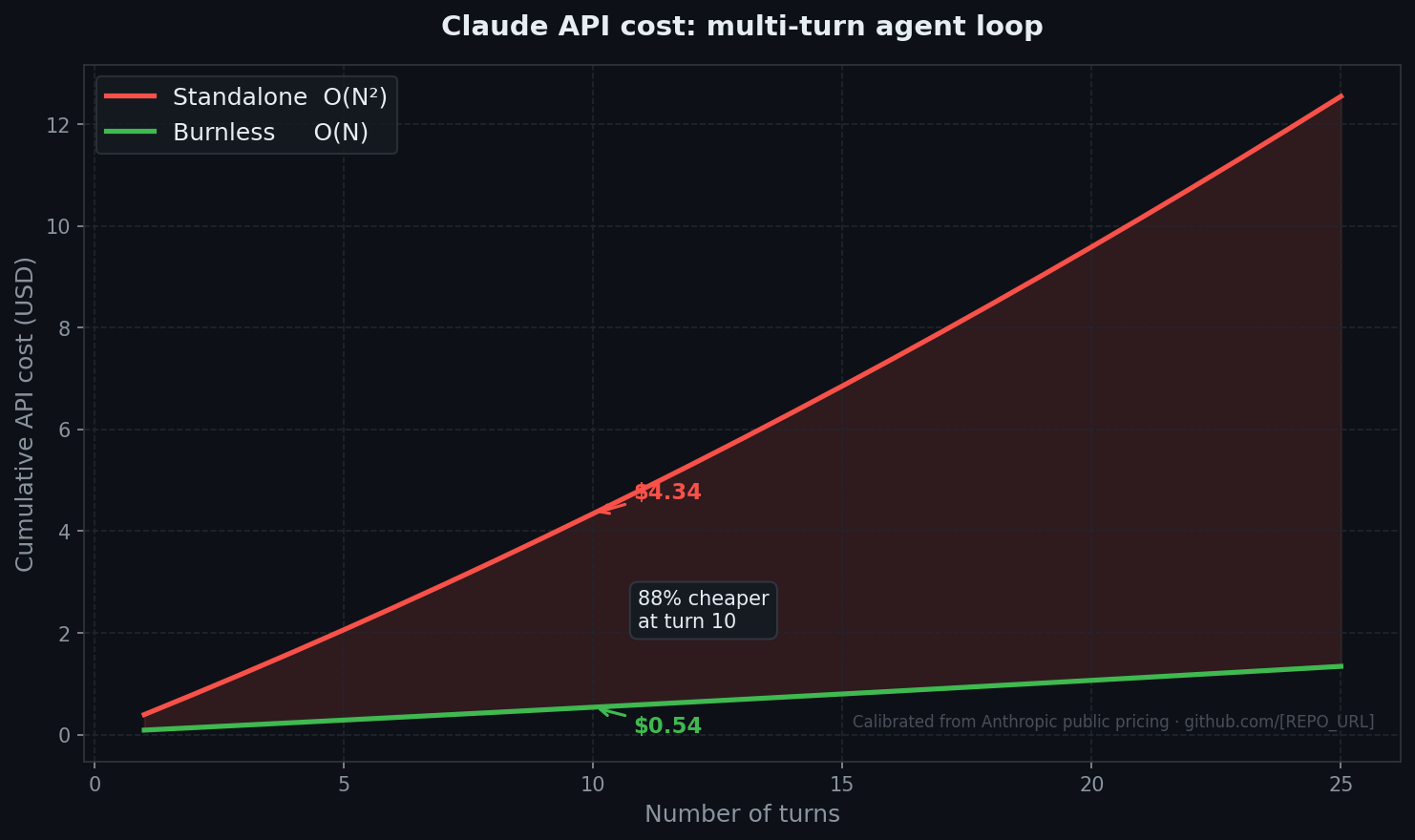
Calibrated from real Anthropic API runs. Reproduce: python bench/v2.py --simulate
Turns Standalone Burnless Savings 2 $0.80 $0.14 82.7% 5 $2.06 $0.29 86.1% 10 $4.34 $0.54 87.6% 20 $9.59 $1.07 88.9% 50 $30.72 $2.83 90.8%
A — No cache, full replay $4.66 B — Cache + full replay $0.65 −86.0% vs A C — Burnless capsules $0.45 −90.3% vs A
response.usage, reproducible with your own key.pip install burnlessgit log. Every number here since is measured, reproducible, or labeled as the anecdote or extrapolation it is. The full note →Beyond cost. The protocol layer.
A token is not an abstraction. It is compute, and compute is electricity. If LLM inference reaches the 1–5% of global electricity that public projections suggest for the next decade, O(N²) replay stops being a pricing quirk and becomes a trajectory.
Burnless is a provider-agnostic layer that sits between any user and any LLM. The model receives a capsule. The user sends a message. The orchestration layer speaks compact state. The contracts — worker envelope, capsule format, tier semantics, audit gates — are written down in PROTOCOL.md, independent of the reference implementation: a protocol in the LSP sense — a specified interface others can implement — not a claim of TCP/IP-scale foundations.
60–90 TWh/year
Back-of-envelope extrapolation (VISION.md) if this pattern reached 1% of global LLM inference. Denmark consumes 35 TWh/year. An extrapolation, not a measurement — check the arithmetic yourself.
Structurally unblockable by design
A semantic capsule is a dense summary of session state sent as ordinary text. The protocol needs no provider-specific feature to carry compact state.
Open, on purpose.
A layer like this will exist. The question is who defines it and in whose interest. Burnless's answer: MIT, documented, contracts public so anyone can implement them.
Why the curve is quadratic.
Every turn in a standalone agent loop replays the full conversation as input. Cost on turn N is proportional to N, so total cost across N turns is Θ(N²). That is arithmetic from the pricing page, not a property of any SDK.
1. Capsules, not transcripts
Brain history holds ~80-char summaries of each turn, not the raw exchange. Full output stays on disk, read on demand.
2. Hot prefix cache
System prompt is byte-identical every turn with cache_control, so it bills at cache-read price — 10% of base input on Anthropic. Caches are per provider and per model; nothing is "shared across models".
3. Tiers are roles, not models
Any model as Brain. Any model as Worker. GPT-4o, Opus, Sonnet, Codex, Ollama — one-line config change.
4. Living glossary
Core terms, project terms and session deltas form a compact language between human intent, Maestro and Workers.
5. Privacy by architecture
Run encoder/decoder locally → cloud sees only capsules, not raw text. Run Maestro locally → cloud workers see disconnected task fragments with zero conversation context. Four levels, one config line.
We don't ask you to trust the table. Reproduce it: python bench/run.py --turns 8 with your own API key.
How it looks.
A chat-first CLI. Slash commands users already understand. Compact state under .burnless/. No hosted backend.
# in any project $ pip install burnless $ burnless setup $ burnless # Burnless Chat — /commands, /maestro, /model, /workers, /native $ burnless delegate "fix the failing tests" → d001 routed to silver/codex (matched: test) $ burnless delegate "summarize the logs" → d002 routed to bronze/haiku (matched: summarize) $ burnless run d002 heartbeat: reading · idle 7s (ephemeral) OK:d002 — typed report + capsule saved
Gold/silver/bronze are quality/cost bands, not vendors. The default setup can mix Claude, Codex and Ollama; users can replace any tier in .burnless/config.yaml.
Cache compaction is realtime ROI math: Burnless freezes immutable blocks and only creates a new super-capsule when future cache-read savings beat the write+compaction cost.
Editions.
The protocol is MIT and stays free. Pay for the things organizations need to trust it at scale: governance, compliance, and team infrastructure.
Burnless
Free · MIT
- Open protocol, MIT licensed
- Full CLI, runs locally
- Brain + Worker + capsule history
- Shared prefix cache, realtime capsule compaction
- Typed execution/thought reports with evidence audit
- Ephemeral heartbeat progress without scroll-history noise
- Local burnkey semantics planned in the protocol
- Provider-agnostic — any LLM as Brain or Worker
- Reproducible benchmark
Burnless Cloud/Enterprise
Soon · waitlist
- Shared cache across machines and teammates
- KMS/HSM key custody and retention policy
- Audit logs, legal hold and destruction reports
- SSO + team permissions
- Dashboards, SIEM/webhooks and priority support
Don't trust the table. python bench/run.py --turns 8 with your own API key.
Burnless Cloud — waitlist.
Hosted features for teams: shared cache, dashboards, KMS/HSM key custody, audit logs, SSO and retention policy. The protocol is free and open source — Cloud/Enterprise is for organizations that need governance.